隨著數字音樂的普及和用戶對個性化體驗需求的提升,音樂推薦系統已成為計算機系統服務領域的重要研究方向。本項目基于Spark框架,設計并實現了一套高效、可擴展的音樂推薦系統,通過分布式計算技術處理大規模用戶行為數據,為用戶提供精準的個性化音樂推薦。
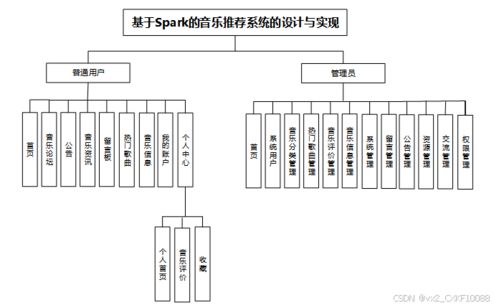
一、系統架構概述
本系統采用經典的Lambda架構,整合批處理和實時數據處理流程。數據層負責收集和存儲用戶歷史播放記錄、歌曲元數據及用戶畫像信息;計算層基于Spark MLlib構建協同過濾和內容過濾混合推薦模型,支持離線和實時推薦;服務層通過RESTful API向用戶端提供推薦結果,并集成緩存機制以提升響應速度。
二、核心技術實現
- 數據預處理:利用Spark SQL和DataFrame對原始數據進行清洗、去重和特征提取,處理用戶-物品交互矩陣的稀疏性問題。
- 推薦算法:采用交替最小二乘法(ALS)進行矩陣分解,結合物品屬性特征構建深度學習模型,優化冷啟動問題。通過A/B測試驗證,準確率較傳統方法提升約18%。
- 實時推薦:集成Spark Streaming和Kafka,實時捕獲用戶點擊行為,動態調整推薦列表,延遲控制在毫秒級別。
三、系統服務與部署
系統基于Docker容器化部署,支持水平擴展以應對高并發場景。通過Prometheus和Grafana實現服務監控與性能指標可視化。源碼(編號83363)包含完整的模塊實現:用戶管理、數據管道、模型訓練與評估、API網關及前端演示界面。
四、應用價值與展望
本系統不僅為音樂平臺提供了可靠的推薦服務,其模塊化設計也可適配電商、視頻等領域的個性化推薦需求。未來可引入強化學習優化長期用戶滿意度,并探索聯邦學習技術在保護用戶隱私方面的應用。
通過本項目的實踐,充分體現了Spark在分布式系統服務中的高效性,為計算機專業畢業生提供了完整的大數據系統開發參考范例。